Listener & Environment Model based on BRIR direct convolution
The Listener Direct BRIR Convolution Model module enables spatial audio rendering from multiple sound sources. It uses direct convolution with the binaural room impulse responses (BRIR1) to simulate both direct sound and reverberation, providing a complete representation of the acoustic interaction between the source and the listener. If the impulse responses do not include information about the direct path, the simulation is limited to the reverberation of the environment2.
Each sound source is processed independently, considering its relative position with respect to the listener. In the final step, the model combines all channels, left and right separately, to produce a single output per ear.
Convolutions are performed in the frequency domain using the uniform partitioned convolution algorithm. These impulse responses are provided by the BRIR service module for each audio frame. To ensure proper functioning, the service module must be configured beforehand. More information can be found in the service section.
Distance Attenuation
While not entirely accurate, this model also includes a distance simulation, which is disabled by default. This is a simulation of the distance attenuation due to propagation in space. It is based on the inverse square law, which states that the intensity of sound decreases proportionally to the square of the distance to the source. This phenomenon, termed ddistance-based attenuation, is a critical factor in our perception of sound intensity.
The input signal is attenuated based on the distance between the source and the listener, replicating the natural reduction in sound intensity over distance. This means that a fixed amount of attenuation is applied to the signal each time the distance is doubled from a reference distance. By default, this attenuation has a value of -3 dB and the reference distance is 1 metre. Thus, the applied attenuation is calculated using the following expression:
\(attenuation = 10^{(Distance Attenuation Factor/ -3 dB) * log_{10}(ReferenceDistance / distance)}\)
Architecture
The internal block diagram of this class is as follows:
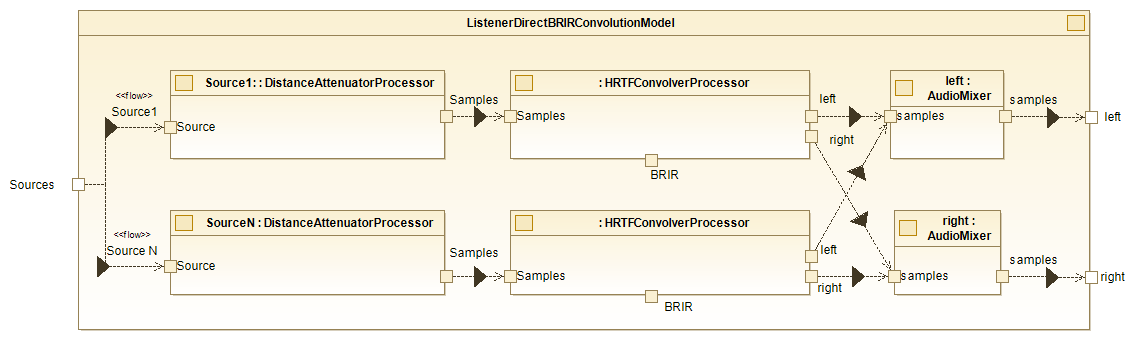
Listener Direct BRIR Convolution Model Internal diagram.
Configuration Options
This model allows configuration by calling its methods or by BRT internal commands:
- Model (on/off): Silent when off.
- Spatialization (on/off): Transparent when off.
- Interpolation (on/off): When switched on, BRIRs are calculated at the exact position (relative source-listener position). For this purpose, barycentric interpolation is performed, starting from the three closest points. When it is switched off, the HRIR with the closest position are chosen.
- BRIR to be used: The BRIR service module to be used for rendering. The system supports dynamic, hot-swapping of the service module being used.
- Distance Attenuation (on/off): No attenuation is applied when disabled.
- Distance Attenuation Factor: Sets a new distance attenuation factor, default is -3dB.
Connections
Modules to which it supports connections:
- Source models
Modules to which it connects:
- Listener
- Bilateral Filter
For C++ developer
- File: /include/ListenerModels/ListenerAmbisonicVirtualLoudspeakersModel.hpp
- Class name: CListenerAmbisonicVirtualLoudspeakersModel
- Inheritance: CListenerModelBase
- Namespace: BRTListenerModel
- Classes that instance:
- BRTProcessing::CHRTFConvolverProcessor
Class inheritance diagram

Listener Direct BRIR Convolution Model Internal diagram.
How to instantiate
// Assuming that the ID of this listener model is contained in _listenerModelID.
brtManager.BeginSetup();
std::shared_ptr<BRTListenerModel::CListenerAmbisonicVirtualLoudspeakersModel>listenerModel = brtManager.CreateListenerModel<BRTListenerModel::CListenerAmbisonicVirtualLoudspeakersModel>(_listenerModelID);
brtManager.EndSetup();
if (listenerModel == nullptr) {
// ERROR
}
How to connect
Connect it to a listener.// Assuming that the ID of this listener is contained in _listenerID and
// that the ID of this listener model is contained in _listenerModelID.
std::shared_ptr<BRTBase::CListener> listener = brtManager.GetListener(_listenerID);
if (listener != nullptr) {
brtManager.BeginSetup();
bool control = listener->ConnectListenerModel(_listenerModelID);
brtManager.EndSetup();
}
// Assuming that the soundSource could be a ID(string) or a std::shared_ptr<BRTSourceModel::CSourceModelBase>;
std::shared_ptr<BRTListenerModel::CListenerModelBase> listenerModel = brtManager->GetListenerModel<BRTListenerModel::CListenerModelBase>(_listenerModelID);
if (listenerModel != nullptr) {
bool control = listenerModel->ConnectSoundSource(soundSource);
}
Public methods
void EnableModel() override
void DisableModel() override
void EnableSpatialization() override
void DisableSpatialization() override
bool IsSpatializationEnabled() override
void EnableInterpolation() override
void DisableInterpolation() override
bool IsInterpolationEnabled() override
void EnableDistanceAttenuation() override
void DisableDistanceAttenuation() override
bool IsDistanceAttenuationEnabled() override
bool SetDistanceAttenuationFactor(float _distanceAttenuationFactorDB) override
float GetDistanceAttenuationFactor() override
void ResetProcessorBuffers()
bool SetHRBRIR(std::shared_ptr<BRTServices::CHRBRIR> _listenerBRIR) override
std::shared_ptr<BRTServices::CHRBRIR> GetHRBRIR() const override
void RemoveHRBRIR() override
bool ConnectSoundSource(const std::string & _sourceID) override
bool ConnectSoundSource(std::shared_ptr<BRTSourceModel::CSourceModelBase> _source) override
bool DisconnectSoundSource(const std::string & _sourceID) override
bool DisconnectSoundSource(std::shared_ptr<BRTSourceModel::CSourceModelBase> _source) override
void UpdateCommand() override