Listener Model based on HRTF convolution in the Ambisonics domain
The Listener Ambisonic Virtual Loudspeakers Model module enables spatial audio rendering from multiple sound sources by simulating the direct path between the source and the listener through convolution in the ambisonic domain. This is based on the impulse responses stored in an HRTF and the selected ambisonic order (currently implemented up to order 3). The process involves two main stages: a bilateral ambisonic encoding and an ambisonic convolution/decoding.
In the first stage, a bilateral ambisonic encoding is performed for each input sound source. This encoding generates (N) ambisonic channels per ear, where (N) depends on the selected ambisonic order. The encoding process begins by introducing independent delays for each ear to simulate interaural time differences (ITD). Subsequently, a near-field correction is applied through independent filtering of the signals for each ear, with filter coefficients determined by the distance between the source and the listener as well as the interaural azimuth. Finally, ambisonic encoding is carried out separately for each ear, resulting in (N) ambisonic channels for each ear per sound source.
In the second stage, two tasks are performed simultaneously: convolution with impulse responses and ambisonic decoding (for more details, see the AmbisonicBIR section). There are two convolution/decoding blocks, one for each ear, allowing independent processing for the left and right channels. Each block begins by separately mixing the ambisonic channels generated during the encoding stage. It then performs convolution in the frequency domain for each channel using precomputed impulse responses stored in the AmbisonicBIR service module. These impulse responses represent the ambisonic mixture of the virtual loudspeaker responses, enabling both convolution and ambisonic decoding to be executed simultaneously. Finally, the output is mixed and transformed back into the time domain, resulting in the final signal for the corresponding ear.
This modular approach ensures efficient and precise spatial audio rendering. The linearity of the operations is leveraged to reduce computational overhead by minimizing the number of convolutions required. The result is a highly realistic simulation of the direct sound path in the ambisonic domain, offering support for scalable ambisonic orders up to the third order.
For further details on the functionality of the Bilateral Ambisonic Encoder and the Ambisonic Domain Convolver, refer to their respective sections in the documentation.
Architecture
The internal block diagram of this class is as follows:
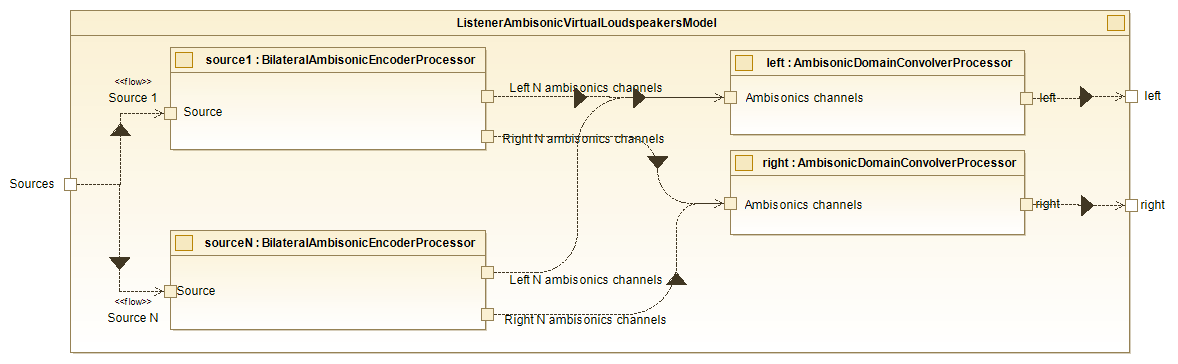
Listener Ambisonic Virtual LoudSpeakers Model - Internal diagram
Configuration Options
This model allows configuration by calling its methods or by BRT internal commands:
- Model (on/off): Silent when off.
- Near Field Compensation (on/off): The near field correction is applied when on.
- ITD Simulation (on/off): When activated, a separate delay is added to each ear to simulate the interaural time difference1. This delay is provided by the HRTF service module and may be provided in the SOFA structure or will be calculated from the head size. When off, it does not simulate interaural time difference.
- Parallax Correction (on/off): When it is switched on, a cross-ear parallax correction is apllied. This correction is based on calculating the projection of the vector from the ear to the source on the HRTF sphere (i.e. the sphere on the surface of which the HRTF was measured), giving a more accurate rendering, especially for near-field and far-field sound sources. When deactivated, the calculation is based on the centre of the listener's head.
- HRTF to be used: The HRTF service module to be used for rendering. The system supports dynamic, hot-swapping of the service module being used.
- Nearfield filter (SOS filter) to be used: The SOS filter service module to be used for rendering. The system supports dynamic, hot-swapping of the service module being used.
- Ambisonic Order: The order of the ambisonic coding to be used. Currently only orders between 1 (default) and 3 are valid.
- Ambisonic Normalization: The ambisonic normalization to be used. The available options are: N3D (default), SN3D, maxN
Connections
Modules to which it supports connections:
- Source models
- Environment models
Modules to which it connects:
- Listener
- Bilateral Filter
For C++ developer
- File: \include\ListenerModels\ListenerAmbisonicVirtualLoudspeakersModel.hpp
- Class name: CListenerAmbisonicVirtualLoudspeakersModel
- Inheritance: CListenerModelBase
- Namespace: BRTListenerModel
- Classes that instance:
- BRTProcessing::CAmbisonicDomainConvolverProcessor
- BRTProcessing::CBilateralAmbisonicEncoderProcessor
Class inheritance diagram

Listener Ambisonic Virtual LoudSpeakers class diagram
How to instantiate
// Assuming that the ID of this listener model is contained in _listenerModelID.
brtManager.BeginSetup();
std::shared_ptr<BRTListenerModel::CListenerAmbisonicVirtualLoudspeakersModel>listenerModel = brtManager.CreateListenerModel<BRTListenerModel::CListenerAmbisonicVirtualLoudspeakersModel>(_listenerModelID);
brtManager.EndSetup();
if (listenerModel == nullptr) {
// ERROR
}
How to connect
Connect it to a listener.// Assuming that the ID of this listener is contained in _listenerID and
// that the ID of this listener model is contained in _listenerModelID.
std::shared_ptr<BRTBase::CListener> listener = brtManager.GetListener(_listenerID);
if (listener != nullptr) {
brtManager.BeginSetup();
bool control = listener->ConnectListenerModel(_listenerModelID);
brtManager.EndSetup();
}
// Assuming that the ID of this listener model is contained in _listenerModelID.
// that the ID of this environment is contained in _environmentModelID.
std::shared_ptr<BRTListenerModel::CListenerModelBase> listenerModel = brtManager.GetListenerModel<BRTListenerModel::CListenerModelBase>(_listenerModelID);
if (listenerModel != nullptr) {
brtManager.BeginSetup();
bool control = listenerModel->ConnectEnvironmentModel(_environmentModelID);
brtManager.EndSetup();
}
// Assuming that the soundSource could be a ID(string) or a std::shared_ptr<BRTSourceModel::CSourceModelBase>;
std::shared_ptr<BRTListenerModel::CListenerModelBase> listenerModel = brtManager->GetListenerModel<BRTListenerModel::CListenerModelBase>(_listenerModelID);
if (listenerModel != nullptr) {
bool control = listenerModel->ConnectSoundSource(soundSource);
}
Public methods
void EnableModel() override
void DisableModel() override
void EnableNearFieldEffect() override
void DisableNearFieldEffect() override
bool IsNearFieldEffectEnabled() override
void EnableITDSimulation() override
void DisableITDSimulation() override
bool IsITDSimulationEnabled() override
void EnableParallaxCorrection() override
void DisableParallaxCorrection() override
bool IsParallaxCorrectionEnabled() override
bool SetAmbisonicOrder(int _ambisonicOrder) override
int GetAmbisonicOrder() override
bool SetAmbisonicNormalization(Common::TAmbisonicNormalization _ambisonicNormalization) override
bool SetAmbisonicNormalization(std::string _ambisonicNormalization) override
Common::TAmbisonicNormalization GetAmbisonicNormalization() override
bool SetHRTF(std::shared_ptr< BRTServices::CHRTF > _listenerHRTF) override
std::shared_ptr<BRTServices::CHRTF> GetHRTF() const override
void RemoveHRTF() override
bool SetNearFieldCompensationFilters(std::shared_ptr<BRTServices::CSOSFilters> _listenerILD) override
std::shared_ptr<BRTServices::CSOSFilters> GetNearFieldCompensationFilters() const override
void RemoveNearFierldCompensationFilters() override
bool ConnectSoundSource(std::shared_ptr<BRTSourceModel::CSourceModelBase> _source) override
bool ConnectSoundSource(const std::string & _sourceID) override
bool DisconnectSoundSource(std::shared_ptr<BRTSourceModel::CSourceModelBase> _source) override
bool DisconnectSoundSource(const std::string & _sourceID) override
bool ConnectEnvironmentModel(const std::string & _environmentModelID) override
bool DisconnectEnvironmentModel(const std::string & _environmentModelID) override
void ResetProcessorBuffers()
void UpdateCommand() override
-
To perform the convolution task correctly, avoiding comb filters, it is necessary that the delays of the impulse responses have been removed. ↩